Acho que é melhor elaborar seu segundo ponto com um exemplo de jogada no jogo 1 entre AlphaZero e Stockfish, que também serviu para satisfazer minha curiosidade hoje.
o limite de tempo de 1 min / movimento (como isso prejudicaria o Stockfish?)
O desempenho do Stockfish depende do tempo limite e da configuração do hardware; portanto, pense em quando alguém duplica os threads da CPU; o Stockfish precisa de menos tempo (não necessariamente a metade) para encontrar a solução do que faria na primeira configuração.
No primeiro relatório publicado no Chess.com, alguém afirmou que o Stockfish não estava sendo reproduzido da melhor maneira possível, porque ele não conseguiu reproduzir os mesmos resultados usando o mesmo Stockfish em seu computador. Ele disse que na posição abaixo (jogo 1 - jogada 11) Stockfish jogou Kg1-h1 (mudou seu rei), o que não fez nenhum sentido. Por outro lado, o bacalhau em seu computador mostrou um movimento mais desenvolvido como o Be3 (mova o bispo do quadrado escuro), vamos olhar para a posição:
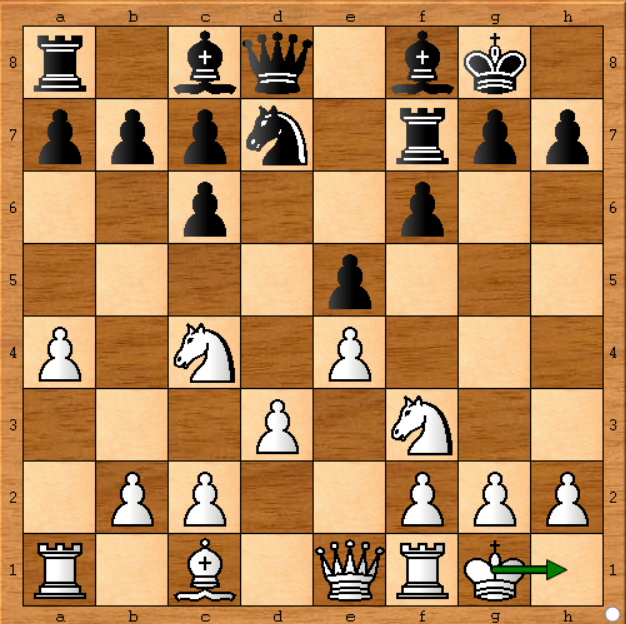
Sim, foi um movimento passivo e parece que o Stockfish deveria ter desempenhado um movimento mais em desenvolvimento. Mas ele estava errado. Por quê? Como ele administrou o Stockfish por 15 segundos, e se ele o executasse por uma hora, ele teria Kg1-h1 como a melhor jogada nessa posição. O Stockfish muda sua decisão quando analisa todos os movimentos possíveis com mais profundidade. Aqui está o que eu disse originalmente na minha resposta :
Corri o último bacalhau na posição (no movimento 11):
- No início, ele fornece b4 como o movimento ideal quando o motor está em funcionamento por cerca de um minuto. Depois disso, ele decide que o Be3 é melhor.
Mas, após 5 minutos no meu hardware que roda em 1.400k nós / s, ele decide usar o Kh1 como a melhor opção.
No artigo, é dito que o bacalhau calcula 70.000k de posições por segundo e é executado por 1 minuto por movimento, ou seja, cerca de 50 vezes o meu hardware, por isso deixarei o meu funcionar por 50 minutos ... Kg1-h1 ainda é o escolha para o Stockfish.
O prazo é a chave
No caso acima, provavelmente não importava muito se o Stockfish funcionasse duas vezes, porque a decisão seria a mesma, mas no próximo passo, definitivamente :
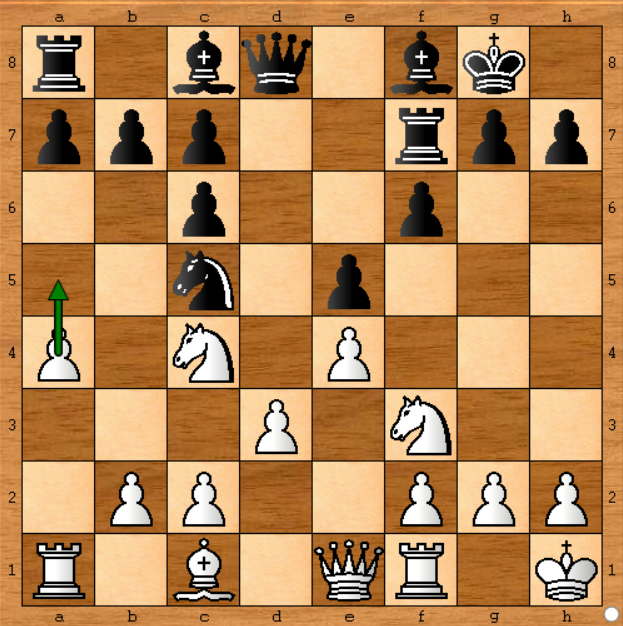
Nesta posição, o Stockfish optou por mover o peão no lado esquerdo ( a4-a5 ). Digamos que eu tenha um computador que execute o mecanismo Stockfish a uma velocidade de 1.400k nós por segundo, cerca de 50 vezes menor que o Stockfish no jogo real ( no documento , ele diz 70.000kn / s). Para simular o jogo, se eu o executar por 50 minutos a cada movimento. OK.
Fiz a análise do Stockfish na posição acima e obtive os seguintes resultados:
- O Stockfish começou sugerindo algumas jogadas, mas após 6 minutos no meu computador (corresponde a 7,2 segundos no Stockfish no jogo real), ele preferiu o a4-a5 exatamente como o jogo foi .
Isso é bom, mas mantive-o funcionando por 50 minutos completos para alcançar os cálculos do Stockfish no jogo que foi permitido em 1 minuto:
A triste verdade é que acredito que o Stockfish perdeu todos os seus jogos por causa do prazo. O Stockfish recebe uma pesquisa e avaliação mais aprofundadas à medida que o tempo passa e, no jogo, não era permitido o uso de um livro de abertura, o que o leva a considerar muitos movimentos em profundidades rasas. Observe que no jogo real a4-a5 foi jogado, o que mostra que (supondo que ele pudesse avaliar 70 milhões de posições por segundo) o Stockfish no jogo não gastou mais de 21,6 segundos em movimento. Caso contrário, ele teria mudado sua decisão para esses três outros movimentos no jogo real. A razão para isso ainda não está clara para mim, pois meu Stockfish também estava consumindo menos memória (cerca de ~ 130 MB de RAM em comparação com 1 GB mencionado no artigo original , supondo que tudo isso vá para tabelas de hash).
Conclusão
O hardware que executava o Stockfish, como apontei, era no máximo 18 vezes mais rápido que o meu (atualização: em um único núcleo), com base na movimentação que analisei. Não tenho certeza se o AlphaZero poderia realmente usar esse hardware para treinar suas redes em 4 horas. Só posso assumir que é muito baixo para um jogo como o xadrez. Além disso, o AlphaZero passou essas horas aprendendo, o que também inclui a construção de aberturas sólidas (e, como o artigo indica, preferências em relação a determinadas aberturas). Por outro lado, o Stockfish foi deficiente em aberturas e não avaliou 70 milhões de posições por segundo durante 60 segundos em cada movimento.
Como nota final, todas as coisas que eu disse foram baseadas em minhas suposições. Claro, o resultado do AlphaZero e os jogos foram super interessantes para mim. No entanto, eu adoraria ver um jogo em que o jogo Stockfish era igual ao que recebo no meu computador também. Ou seja, mais tempo e um livro de abertura permitido. Também é fácil obter os resultados da análise do Stockfish a cada movimento, e eu desejo que eles a divulguem para mostrar o desempenho.