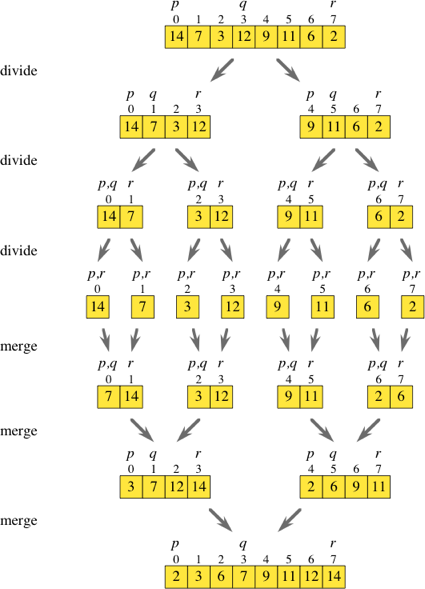
Portanto, a classificação por mesclagem é um algoritmo de divisão e conquista. Enquanto eu observava o diagrama acima, estava pensando se era possível ignorar basicamente todas as etapas de divisão.
Se você iterou sobre a matriz original enquanto pulava duas vezes, poderia obter os elementos no índice iei + 1 e colocá-los em suas próprias matrizes ordenadas. Depois de ter todas essas sub-matrizes ([7,14], [3,12], [9,11] e [2,6], como mostrado no diagrama), você pode simplesmente prosseguir com a rotina de mesclagem normal para obter uma matriz classificada.
A iteração na matriz e a geração imediata das sub-matrizes necessárias são menos eficientes do que as etapas de divisão na sua totalidade?
Veja também: cs.stackexchange.com/questions/77075/…
—
Omar