Preciso validar um nome de domínio:
google.com
stackoverflow.com
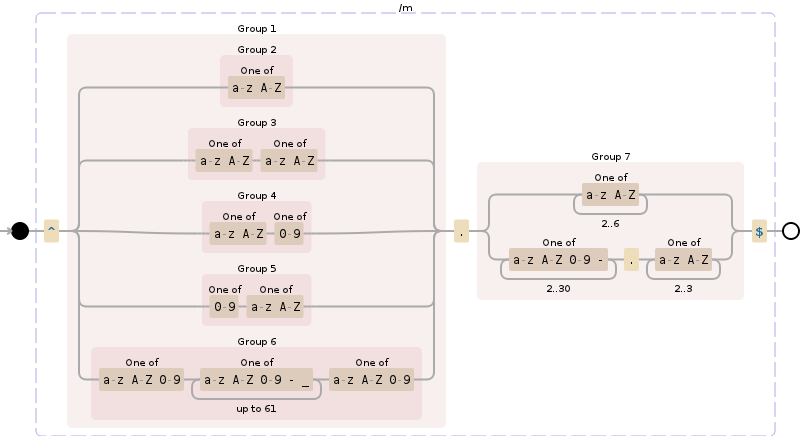
Portanto, um domínio em sua forma mais bruta - nem mesmo um subdomínio como www.
- Os caracteres devem ser apenas az | AZ | 0-9 e ponto (.) E traço (-)
- A parte do nome do domínio não deve começar ou terminar com traço (-) (por exemplo, -google-.com)
- A parte do nome do domínio deve ter entre 1 e 63 caracteres
A extensão (TLD) pode ser qualquer coisa sob as regras nº 1 por enquanto. Posso validá-las em uma lista posteriormente, mas deve ter 1 ou mais caracteres.
Edit: TLD é aparentemente 2-6 caracteres, tal como está
não. 4 revisado: o TLD deve realmente ser rotulado como "subdomínio", pois deve incluir coisas como .co.uk - eu imaginaria que a única validação possível (além de verificar em uma lista) seria 'após o primeiro ponto, deve haver um ou mais personagens sob as regras # 1
Muito obrigado, acredite, eu tentei!
1
Pode não ser de todo útil. Quando se trata de google.co.uk e de alguns domínios japoneses, tenho certeza que você precisará pensar duas vezes antes de usar o regex para isso. Meu pensamento pessoal é que o regex não é suficiente para validar um domínio para um domínio da vida real. FYI, aqui está uma lista quase completa de DPNs e código do país lista de domínios de segundo nível: static.ayesh.me/misc/SO/tlds.txt
—
Ayesh K
Veja minha resposta para a pergunta relacionada sobre validação de nome de host .
—
SAM
Muitas vezes esquecido: para nomes de domínio totalmente qualificados, você deve corresponder a um período após o tld.
—
22413 schmijos
tem sido de 4 anos, agora a contagem é de até 89.000
—
mydoglixu
Algumas dessas respostas são muito boas, mas há outra boa resposta a essa outra pergunta que vale a pena dar uma olhada.
—
craftworkgames