Eu tenho essa pergunta há meses. Parece que acabamos de adivinhar inteligentemente o softmax como uma função de saída e depois interpretar a entrada no softmax como log-probabilidades. Como você disse, por que não simplesmente normalizar todas as saídas dividindo por sua soma? Encontrei a resposta no livro Deep Learning de Goodfellow, Bengio e Courville (2016) na seção 6.2.2.
Digamos que nossa última camada oculta nos dê z como uma ativação. Então o softmax é definido como

Explicação muito curta
A exp na função softmax cancela aproximadamente o log na perda de entropia cruzada, fazendo com que a perda seja aproximadamente linear em z_i. Isso leva a um gradiente aproximadamente constante, quando o modelo está errado, permitindo que ele se corrija rapidamente. Assim, um softmax saturado errado não causa um gradiente de fuga.
Breve explicação
O método mais popular para treinar uma rede neural é a estimativa de máxima verossimilhança. Estimamos os parâmetros theta de maneira a maximizar a probabilidade dos dados de treinamento (de tamanho m). Como a probabilidade de todo o conjunto de dados de treinamento é um produto das probabilidades de cada amostra, é mais fácil maximizar a probabilidade de log do conjunto de dados e, portanto, a soma da probabilidade de log de cada amostra indexada por k:
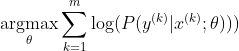
Agora, focamos apenas o softmax aqui com z já fornecido, para que possamos substituir
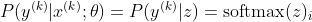
sendo eu a classe correta da k-ésima amostra. Agora, vemos que, quando tomamos o logaritmo do softmax, para calcular a probabilidade de log da amostra, obtemos:
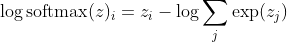
, que para grandes diferenças em z aproxima-se aproximadamente de
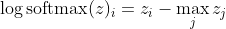
Primeiro, vemos o componente linear z_i aqui. Em segundo lugar, podemos examinar o comportamento de max (z) em dois casos:
- Se o modelo estiver correto, max (z) será z_i. Portanto, a probabilidade de log atribui zero (ou seja, uma probabilidade de 1) com uma diferença crescente entre z_i e as outras entradas em z.
- Se o modelo estiver incorreto, max (z) será outro z_j> z_i. Portanto, a adição de z_i não cancela completamente -z_j e a probabilidade de log é aproximadamente (z_i - z_j). Isso diz claramente ao modelo o que fazer para aumentar a probabilidade de log: aumente z_i e diminua z_j.
Vemos que a probabilidade geral de log será dominada por amostras, onde o modelo está incorreto. Além disso, mesmo se o modelo estiver realmente incorreto, o que leva a um softmax saturado, a função de perda não satura. É aproximadamente linear em z_j, o que significa que temos um gradiente aproximadamente constante. Isso permite que o modelo se corrija rapidamente. Observe que esse não é o caso do erro médio quadrático, por exemplo.
Explicação longa
Se o softmax ainda parecer uma escolha arbitrária para você, dê uma olhada na justificativa para usar o sigmoide na regressão logística:
Por que a função sigmóide em vez de qualquer outra coisa?
O softmax é a generalização do sigmóide para problemas de várias classes justificados analogamente.



