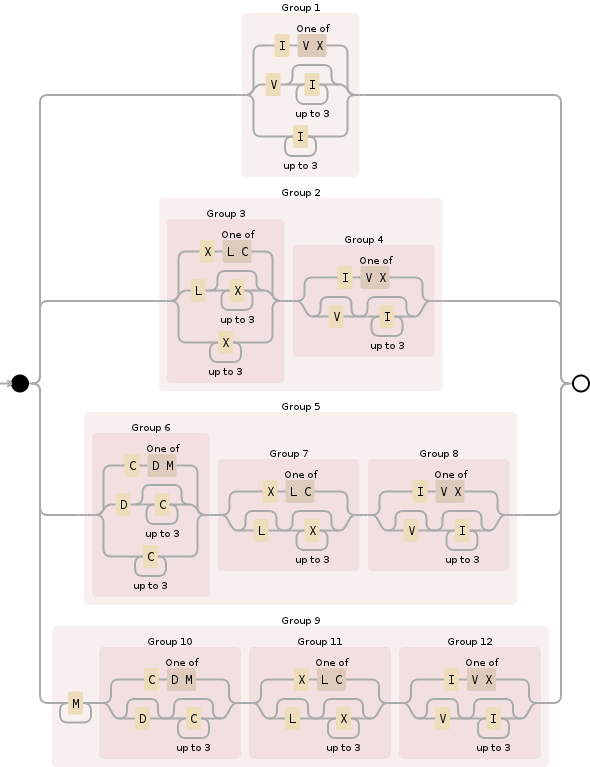
Você pode usar o seguinte regex para isso:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Dividindo, M{0,4}especifica a seção milhares e basicamente a restringe a entre 0e 4000. É relativamente simples:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Obviamente, você poderia usar algo como M*para permitir qualquer número (incluindo zero) de milhares, se desejar permitir números maiores.
A seguir (CM|CD|D?C{0,3}), um pouco mais complexo, isso é para a seção de centenas e abrange todas as possibilidades:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
Em terceiro lugar, (XC|XL|L?X{0,3})segue as mesmas regras da seção anterior, mas para o lugar das dezenas:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
E, finalmente, (IX|IV|V?I{0,3})é a seção unidades, a manipulação 0através de 9e também semelhante às duas seções anteriores (algarismos romanos, apesar de sua estranheza aparente, seguir algumas regras lógicas uma vez que você descobrir o que eles são):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Lembre-se de que esse regex também corresponderá a uma sequência vazia. Se você não deseja isso (e seu mecanismo de expressão regular é moderno o suficiente), pode usar um look-behind e um look-ahead positivos:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(a outra alternativa é apenas verificar se o comprimento não é zero antes).