Verifique o RTEFC ("Clustering de filtro exponencial em tempo real") ou o RTMAC ("Clustering de média móvel em tempo real), que são variantes simples e eficazes em tempo real dos meios K, adequadas para uso em tempo real quando o protótipo de cluster é apropriado. Eles agrupam sequências Consulte https://gregstanleyandassociates.com/whitepapers/BDAC/Clustering/clustering.htm
e o material associado sobre a representação de séries temporais multivariadas como um vetor maior a cada etapa do tempo (a representação para "BDAC"), com um deslizante janela de tempo.
Eles foram desenvolvidos para realizar simultaneamente a filtragem de ruído e o agrupamento em tempo real para reconhecer e rastrear diferentes condições. O RTMAC limita o crescimento da memória mantendo as observações mais recentes próximas a um determinado cluster. O RTEFC retém os centróides apenas de uma etapa para a outra, o que é suficiente para muitos aplicativos. Pictoricamente, a RTEFC se parece com:
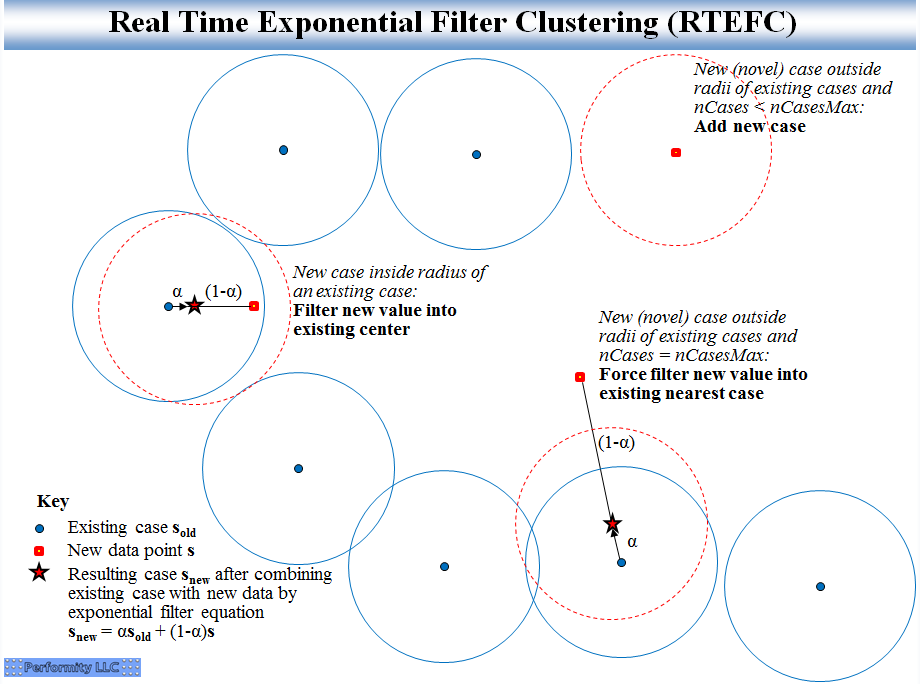
Dawg pediu para comparar isso com o HDBSCAN, em particular a função approx_predict (). A principal diferença é que o HDBSCAN ainda está assumindo que há ocasional reciclagem de pontos de dados originais, uma operação cara. A função HDBSCAN approx_predict () é usada para obter uma atribuição rápida de cluster para novos dados sem reciclagem. No caso da RTEFC, nunca há um cálculo grande de reciclagem, porque os pontos de dados originais não são armazenados. Em vez disso, apenas os centros de cluster são armazenados. Cada novo ponto de dados atualiza apenas um centro de cluster (criando um novo, se necessário, e dentro do limite superior especificado no número de clusters ou atualizando um centro anterior). O custo computacional em cada etapa é baixo e previsível.
As imagens têm algumas semelhanças, exceto que a imagem HDBSCAN não teria o ponto com estrela, indicando um centro de cluster recomputado para um novo ponto de dados próximo a um cluster existente, e a imagem HDBSCAN rejeitaria o novo caso de cluster ou o caso de atualização forçada como outliers.
O RTEFC também é opcionalmente modificado quando a causalidade é conhecida a priori (quando os sistemas definem entradas e saídas). As mesmas entradas do sistema (e condições iniciais para sistemas dinâmicos) devem produzir as mesmas saídas do sistema. Eles não o fazem devido a ruídos ou alterações no sistema. Nesse caso, qualquer métrica de distância usada para clustering é modificada para considerar apenas a proximidade das entradas do sistema e das condições iniciais. Portanto, devido à combinação linear de casos repetidos, o ruído é parcialmente cancelado e ocorre uma lenta adaptação às alterações do sistema. Os centróides são na verdade melhores representações do comportamento típico do sistema do que qualquer ponto de dados específico, devido à redução de ruído.
Outra diferença é que tudo o que foi desenvolvido para o RTEFC é apenas o algoritmo principal. É simples o suficiente para implementar com apenas algumas linhas de código, que é rápido e com tempo de computação máximo previsível em cada etapa. Isso difere de uma instalação inteira com muitas opções. Esses tipos de coisas são extensões razoáveis. A rejeição externa, por exemplo, poderia simplesmente exigir que, após algum tempo, pontos fora da distância definida para um centro de cluster existente fossem ignorados, em vez de usados para criar novos clusters ou atualizar o cluster mais próximo.
Os objetivos da RTEFC são terminar com um conjunto de pontos representativos, definindo o possível comportamento de um sistema observado, adaptar-se às mudanças do sistema ao longo do tempo e, opcionalmente, reduzir o efeito do ruído em casos repetidos com causalidade conhecida. Não é para manter todos os dados originais, alguns dos quais podem se tornar obsoletos à medida que o sistema observado muda com o tempo. Isso minimiza os requisitos de armazenamento e o tempo de computação. Esse conjunto de características (os centros de cluster como pontos representativos são tudo o que é necessário, adaptação ao longo do tempo, previsível e baixo tempo de computação) não servirão para todos os aplicativos. Isso pode ser aplicado à manutenção de conjuntos de dados de treinamento on-line para agrupamento orientado a lotes, modelos de aproximação de função de rede neural ou outro esquema para análise ou construção de modelo. Exemplos de aplicações podem incluir detecção / diagnóstico de falhas; controle do processo; ou outros locais onde modelos podem ser criados a partir de pontos representativos ou comportamento interpolado entre esses pontos. Os sistemas observados seriam aqueles descritos principalmente por um conjunto de variáveis contínuas, que de outra forma poderiam exigir modelagem com equações algébricas e / ou modelos de séries temporais (incluindo equações de diferença / equações diferenciais), bem como restrições de desigualdade.