Eu tenho um aplicativo baseado em servlet em que medo o tempo necessário para concluir cada solicitação desse servlet. Eu já calculo estatísticas simples como média e máximo; No entanto, gostaria de produzir uma análise mais sofisticada e, para isso, acredito que preciso modelar adequadamente esses tempos de resposta.
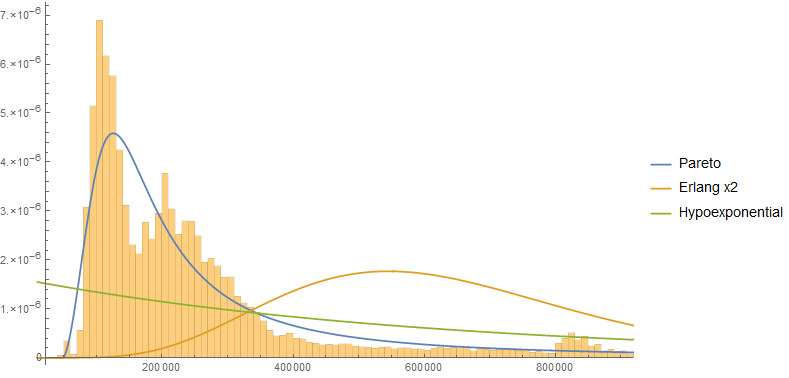
Certamente, digo, os tempos de resposta seguem uma distribuição bem conhecida, e há boas razões para acreditar que a distribuição é o modelo certo. No entanto, não sei o que essa distribuição deveria ser.
Lembre-se de Log-normal e Gamma, e você pode ajustar um dos tipos de dados de tempo de resposta real. Alguém tem uma visão sobre qual distribuição os tempos de resposta devem seguir?