Ken já resumiu algumas das razões em sua resposta . Para expandir ainda mais
- Mais cache , mais rápido que a RAM
Caches obviamente maiores precisam de mais transistores. Mas com mais transistores, também temos a opção de usar caches mais rápidos . Caches de CPU são apenas SRAM, normalmente feitos de 6 transistores (AKA 6T SRAM). No entanto, quando existem transistores suficientes, pode valer a pena usar células SRAM mais rápidas, porém maiores, feitas com mais de 6 transistores (como 8T, 10T SRAM)
- Mais instruções SIMD , que processam mais rápido que as instruções de dados únicos
Não apenas SIMD, mas qualquer tipo de instruções de aceleração. Por exemplo, as arquiteturas modernas costumam ter uma unidade AES para criptografia / descriptografia mais rápida, FMA para melhor computação matemática (especialmente processamento de sinal digital) ou virtualização para máquinas virtuais mais rápidas. Suportar mais instruções significa que são necessários mais recursos para decodificá-los e executá-los
- Mais núcleos , para que você possa fazer duas ou mais coisas ao mesmo tempo
- Pipelines , para que cada núcleo possa fazer mais coisas ao mesmo tempo
Estes são bastante claros
- Unidades mais funcionais, como built-in FPU s, e múltipla ALU s
No passado, não havia uma área de matriz suficiente para a FPU, portanto, as pessoas deveriam comprar uma área separada se tivessem altos requisitos de aritmética de ponto flutuante. Com significativamente mais transistores, é possível ter o FPU embutido, acelerando muito a matemática de ponto flutuante
Além disso, as CPUs modernas são superescalares e tentam fazer várias coisas ao mesmo tempo , encontrando dados independentes e calculando-os mais cedo, mesmo que o fluxo de instruções seja linear e serial. Quanto mais coisas eles puderem fazer em paralelo, mais rápido eles serão. Para fazer isso, uma CPU pode ter várias ALUs e uma ALU pode ter várias unidades de execução. Se, por exemplo, uma CPU possui 5 adicionadores em comparação com 4 na geração anterior, ela já está rodando 25% mais rápido na situação mais otimista, sem alterações no relógio. CPUs mais sofisticadas ainda empregam execução fora de ordem (que é o caso da maioria das CPUs de alto desempenho modernas)
As operações normalmente podem ser realizadas de várias maneiras. Se você tiver mais transistores, terá mais recursos para usar uma técnica mais rápida. Alguns exemplos simples:
Mudança de bit:
Um simples shifter é feito ao conectar serialmente os chinelos.

Isso precisa de apenas um flip-flop por bit, portanto, extremamente compacto. Mas ele precisa de um relógio para mudar um pouco para a esquerda ou direita. É por isso que os microcontroladores e as pequenas CPUs incorporadas têm apenas instruções para mudar uma a uma. Vejo
Quando você tiver mais transistores para gastar, poderá mudar para um shifter de barril . Agora, uma CPU pode mudar bits em um único relógio com o custo de centenas ou milhares de transistores
Adição:
- Um somador simples também é feito ao conectar somadores completos em série. Dessa forma, um somador de N bits precisa de relógios N para concluir seu trabalho, o que certamente não é o que as pessoas esperam em uma CPU
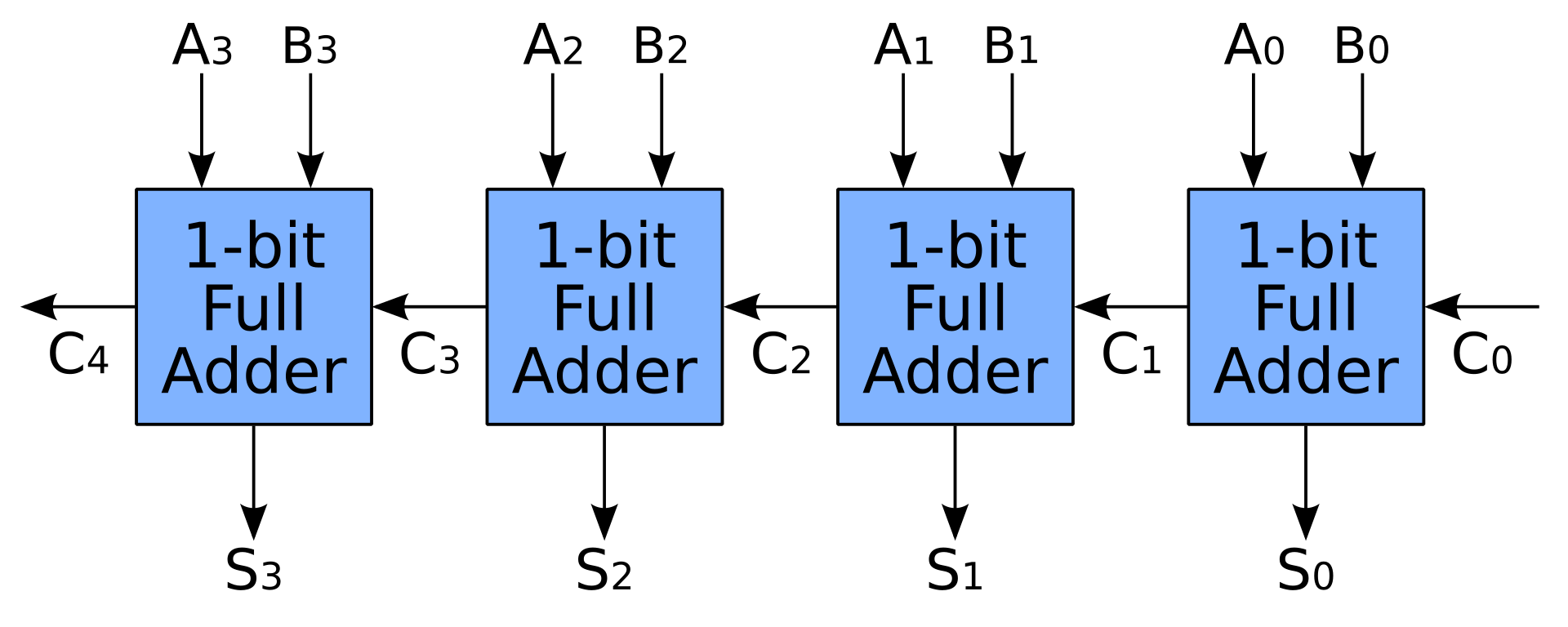
- Com mais transistores, podemos acelerar a adição pré-calculando os carregamentos com carry-lookahead ou carry-save somador. Os somadores completos ainda são usados, mas é necessário muito mais espaço para a unidade de pré-cálculo de transporte
O mesmo se aplica a outras unidades, como multiplicadores, divisores, agendador ... Por exemplo, podemos fazer uma multiplicação extremamente rápida em um único relógio usando a lógica combinacional . Você pode ver alguns exemplos simples na pergunta multiplicadores de 3 bits - como eles funcionam? . Mas os transistores necessários aumentarão para o quadrado das larguras de entrada; portanto, pequenas CPUs com um multiplicador usam a lógica seqüencial em vez disso, para economizar muito espaço para o multiplicador:
As arquiteturas multiplicadoras mais antigas empregavam um shifter e um acumulador para somar cada produto parcial, geralmente um produto parcial por ciclo, trocando a velocidade pela área da matriz. As arquiteturas multiplicadoras modernas usam o algoritmo de Baugh – Wooley (modificado), árvores Wallace ou multiplicadores Dadda para adicionar produtos parciais em um único ciclo. Às vezes, o desempenho da implementação da árvore Wallace é aprimorado pela Booth modificada que codifica um dos dois multiplicandos, o que reduz o número de produtos parciais que devem ser somados
https://en.wikipedia.org/wiki/Binary_multiplier#Implementations
Depois de ter um enorme conjunto de transistores, você pode até usar a lógica combinacional para criar uma FMA que consome muito mais recursos do que um multiplicador
Os computadores modernos podem conter um MAC dedicado, consistindo em um multiplicador implementado na lógica combinacional seguida por um somador e um registro acumulador que armazena o resultado. A saída do registro é retornada a uma entrada do somador, de modo que, a cada ciclo do relógio, a saída do multiplicador é adicionada ao registro. Os multiplicadores combinacionais exigem uma grande quantidade de lógica, mas podem computar um produto muito mais rapidamente do que o método de troca e adição típico de computadores anteriores.
Operação multiplicar-acumular

#/media/File:1-bit_full-adder.svg)