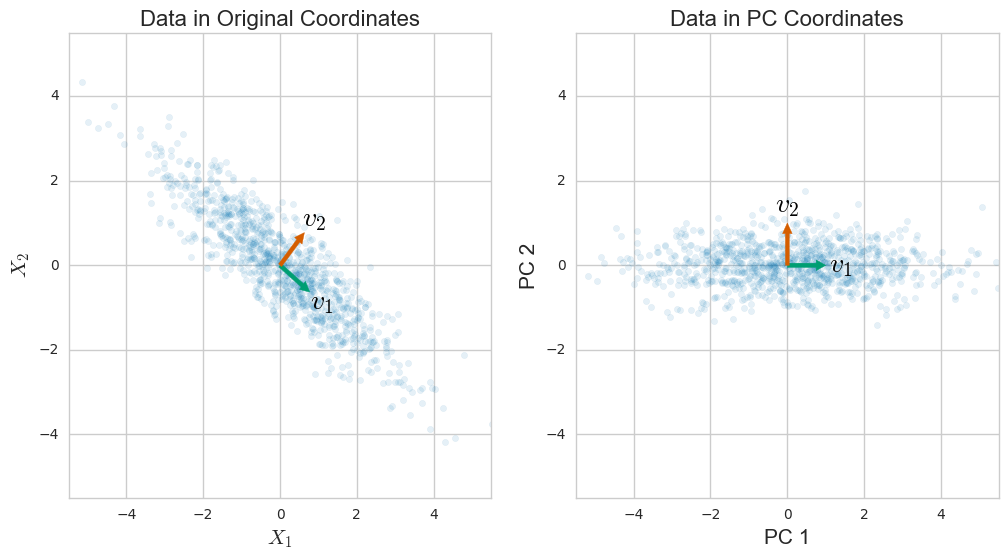
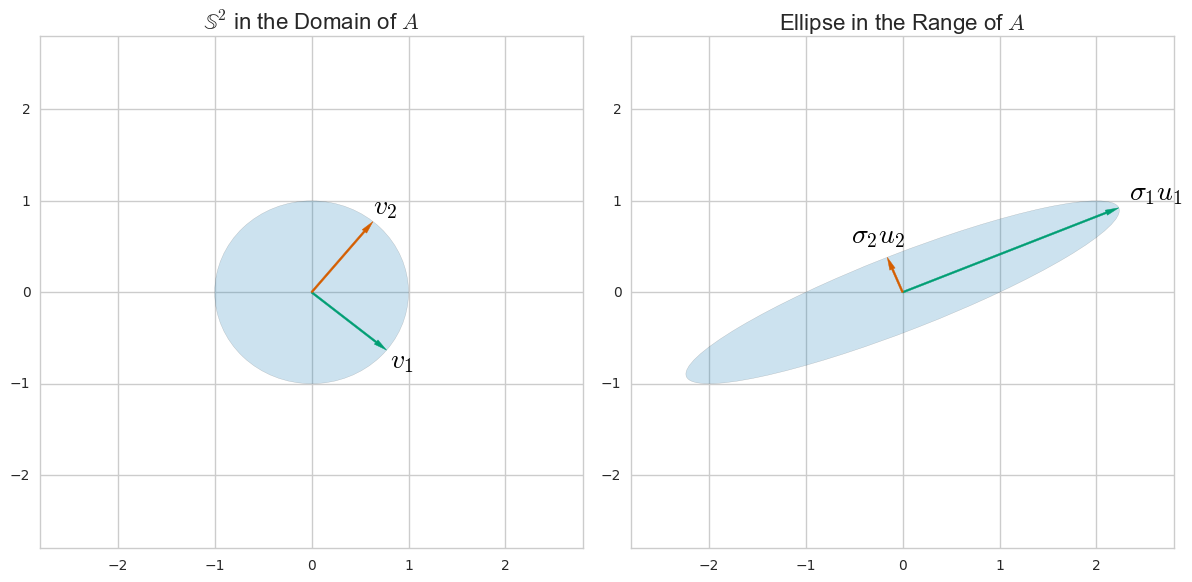
A análise de componentes principais (PCA) é geralmente explicada por meio de uma decomposição por si própria da matriz de covariância. No entanto, também pode ser realizado via decomposição de valor singular (SVD) da matriz de dados . Como funciona? Qual é a conexão entre essas duas abordagens? Qual é a relação entre SVD e PCA?
Ou, em outras palavras, como usar o SVD da matriz de dados para realizar a redução da dimensionalidade?
8
Eu escrevi essa pergunta no estilo FAQ juntamente com a minha própria resposta, porque ela é frequentemente solicitada de várias formas, mas não há thread canônico e, portanto, é difícil fechar duplicatas. Forneça meta comentários neste meta thread em anexo .
—
Ameba
Além da excelente e detalhada resposta da ameba com seus links adicionais, eu recomendo verificar isso , onde o PCA é considerado lado a lado algumas outras técnicas baseadas em SVD. A discussão lá apresenta álgebra quase idêntica à da ameba, com apenas uma pequena diferença de que o discurso ali, ao descrever o PCA, trata da decomposição de X / √ no svd [ouX/ √ ] em vez de X- o que é simplesmente conveniente no que se refere ao PCA feito através da composição automática da matriz de covariância.
—
ttnphns
PCA é um caso especial de SVD. O PCA precisa dos dados normalizados, idealmente mesma unidade. A matriz é nxn no PCA.
—
Orvar Korvar
@OrvarKorvar: De que matriz nxn você está falando?
—
Cbhihe